


媒体说能给我提供数据?到底能提供什么数据?
 宋星的数字观
宋星的数字观 2年前
 收藏 0
收藏 0
 2
2
 分享
分享



【摘要】:所谓的提供数据,到底有哪些方式?又能提供什么样的数据。
广告主渴望获得数据。
但是,获得数据的路子似乎越来越窄,窄到当有媒体(或者第三方)跟我们说,我们能给你提供数据的时候,我们会觉得异常兴奋。
兴奋之余,要冷静。这个时候,如同我们在工作中常常会有的好习惯——那就是,不要模模糊糊,而是要搞清楚,到底是什么情况——就会对我们非常有用。
这篇文章,我想快速跟大家聊聊,所谓的提供数据,到底有哪些方式,又能提供什么样的数据。
全文大纲
1.媒体(或其他第三方)为企业“提供”数据的四种情况
2.第一种方式:Raw Data转移的场景
3.第二种方式:ID匹配后转移命中的个体级别属性或部分属性的场景
4.第三种方式:ID匹配后提供统计报告
5.第四种方式:横向联邦学习或者迁移联邦学习方式
6.总结
媒体(或其他第三方)为企业“提供”数据的四种情况

上图:为企业“提供”数据的四种情况。
请注意,就像我在上面的图中所描述的,媒体(或其他第三方)为企业提供数据,是有各种方式的。你所认为的数据提供,和他们为你进行的“提供”,很可能压根就有很大的区别。
这四种数据提供的方式,分别是:
第一种:直接把原始数据(Raw Data)拷贝给你,数据发生了物理上的转移(复制、下载等)。所谓Raw Data,是指关于用户的一条一条的行为、属性、兴趣等各种原始的记录。
第二种:不直接拷贝给你Raw Data,但是跟你手中所拥有的用户进行ID的匹配。匹配之后,把能够匹配命中的ID项下的属性数据(或部分属性数据)转移给你。这些数据都是按照ID分为一条一条的,所以是个体级别的数据。ID的匹配,在《个保法》出台之前,大家常常以明文的方式进行匹配,而现在则几乎都是通过加密ID再进行匹配的方式,甚至会用到更高安全级别的加密ID匹配,即采用隐私计算中的纵向联邦学习的方式。
第三种:跟第二种类似,同样要进行ID匹配,只不过匹配之后,不是把命中的ID项下的属性数据给你,而是把所有命中的ID的属性数据进行统计整理,然后把统计结果以报告的形式转移给你。
第四种:是相对比较烧脑的一种方式,在这种方式下,数据不进行ID的匹配,而是数据提供方(暂且这么叫吧,因为压根就没有提供实际数据)和广告主分别计算模型,并向各自返回模型和计算结果。这种方式常常采用联邦迁移学习的高段位方法,也有采用广告主和数据提供方选取同样的属性字段各自计算模型之后再优化模型的横向联邦学习的方法的。但总体是一种理论上ok,但实际操作起来十分“缥缈”的玩法。各种具体的联邦学习的方式,大家如果感兴趣,我会在我的“宋星大课堂:《数字化增长——以消费者为核心的数字营销的 转型、路径与落地》”上介绍。
下面,我来讲讲各种方式下,常用的数据“提供”的场景和价值。
第一种方式:Raw Data转移的场景
听说用卡车运送硬盘,是目前大数据量数据转移速度最快的方式,能到达大概每秒100个G。但这样的数据转移,基本上只可能发生在企业内部,比如阿里就用过这样的方法转移他们的数据。
不过,用卡车运,如果万一路上出个车祸——不敢想,不敢想。
回到我们的场景中。无论是媒体,还是外部数据提供方,现在都不太可能给企业提供Raw Data。很多年前确实有这样的生意,而且很普遍,有些人还因此发家买了很多套房。但隐私保护、个人信息保护以及数据安全的法律逐渐完善起来之后,这样的场景基本上没有了。
不过,只是基本上没有。如同任何不合法的交易都存在黑市一样,Raw Data数据转移也有黑市。别问我这些黑市在哪儿,我也不知道,而且正经企业不会问我这个问题。
第二种方式:ID匹配后转移命中的个体级别属性或部分属性的场景
当你看到我写出了个体级别四个字,你可能会认为,这种情形应该也不存在了——没有什么媒体还愿意给广告主个体级别的数据了。但事实上,这种数据转移仍然是有场景的。
电商平台的会员通,会跟广告主的会员,在进行ID匹配(通常是用加密的电话号码)之后,提供给广告主该ID的部分与会员权益等相关的数据,这些数据是个体级别的。
微信生态,微信也会在用户授权的情形下,利用OpenID或者UnionID,经由API,给广告主提供个体级别用户的部分行为或属性数据。
所以,不像第一种方式,第二种方式仍然是常见的数据提供的方式。
但是,这种方式显然有一个很值得注意的点,那就是,提供的个体级别的属性数据能包含什么,是由媒体圈定范围,并由用户实际授权同意之后,才可能发生的。
所以,通常这些数据的类型会很有限。
第三种方式:ID匹配后提供统计报告
这也是一种常见的场景,而且基本上符合法律所规定的个人信息保护的合规要求。
例如,广告主将自己CDP中圈选的人群的ID加密后(或纵向联邦学习的方式),与媒体的DMP中用户的ID进行匹配。匹配后,媒体把这部分人的属性进行统计整理,以所谓的“人群画像”的方式提供给广告主。
这种方式,基本上用于做人群画像或者人群洞察了。
虽然对于精细化运营每一个用户或者每一个消费者并无直接作用,但是在帮助形成营销策略上,是很有价值的。
第四种方式:横向联邦学习或者迁移联邦学习方式
在深度利用企业的CDP方面,需要用到此种方式。
但是,大部分企业可能都难以拥有这样的能力。
一个简单的应用,以汽车行业为例。汽车行业的主机厂,拥有很多用户在私域触点上的各种行为数据,这些数据例如“看了某个车型介绍的次数”或者“查看汽车金融的次数”或是“在某类车型页面上的停留时间”。而媒体也有完全一样类型的这样的数据(比如腾讯汽车或者懂车帝也有类似的数据)。然后,二者各自基于这些数据类型和一个通用模型进行计算,并各自得出一个比通用模型更优化的模型,该模型能判断这些数据的值具体是什么情况时,用户就会表现出较为明确的愿意“留资(就是有购车意向)”的倾向。之后,二者将各自的模型互相传递,再基于两个优化模型得出一个更新的通用模型,随之再把这个新的通用模型给二者,并基于更多的数据,再做计算,各自再得出一个更更优化的模型……
这个过程循环n次,直到得到一个满意的通用模型,两边都能拿着用于预测各自的用户是否有购车意向。——这就是横向联邦学习。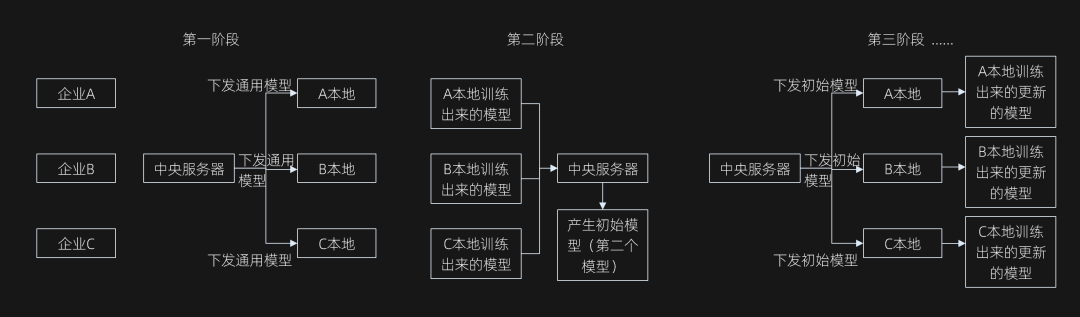
上图:横向联邦学习的示意过程。
联邦迁移学习则更加“牛”,不过比较复杂,就大致说一下。简单说,就是媒体和广告主,不仅双方ID不允许做任何匹配,就连用户的属性数据类型都不一样,比如媒体只有“看了某个车型介绍的次数”或者“查看汽车金融的次数”的数据类型,而车企只有“在某类车型页面上的停留时间”的数据类型。然后二者还是要得到一个更优化的预测用户是否可能留资的模型。
所以,如同我讲的车企的例子,第四种方式常常用于预测和人工智能判断。通常无论是广告主还是媒体,都需要相当大体量且类型丰富的数据。
因此,这种方式,听起来就已经很“玄学”,落地实现起来就更加困难了。也不是没有企业这么做,但是,真的很少。
总结
现在,你再看看你的媒体跟你承诺的,要提供给你数据,是什么情况?
大部分,我相信,都是第二种和第三种。尤其是第三种,特别多。
你所期待的,全量的Raw Data的提供(也就是第一种),在今天恐怕越来越难以实现。
本文由广告狂人作者: 宋星的数字观 发布,其版权均为原作者所有,文章为作者独立观点,不代表 广告狂人 对观点赞同或支持,未经授权,请勿转载,谢谢!

2
-已有2位广告人觉得这个内容很不错-


相关推荐







畅言一下
后发布评论
0/1000
全部评价






 联系我们
联系我们
